| Name | Last modified | Size | Description | |
|---|---|---|---|---|
| 0059.gif | 1997-07-03 18:07 | 72K | ||
| ImgVR_test.java | 2001-07-20 15:19 | 3.1K | ||
| Makefile | 2001-07-10 18:11 | 1.0K | ||
| README | 2003-01-23 18:06 | 4.7K | ||
| SLAM/ | 2004-07-06 14:04 | - | ||
| absolute10.gif | 1997-07-21 12:14 | 24K | ||
| aerials/ | 1998-12-21 10:15 | - | ||
| aerials2/ | 1999-01-15 13:03 | - | ||
| all_trans_locs.txt | 2001-07-27 11:21 | 30K | ||
| argus_nodes.jpg | 1999-01-26 21:16 | 22K | ||
| aug97cart.gif | 1997-10-27 17:33 | 262K | ||
| autooutput.jpg | 1999-01-20 19:17 | 57K | ||
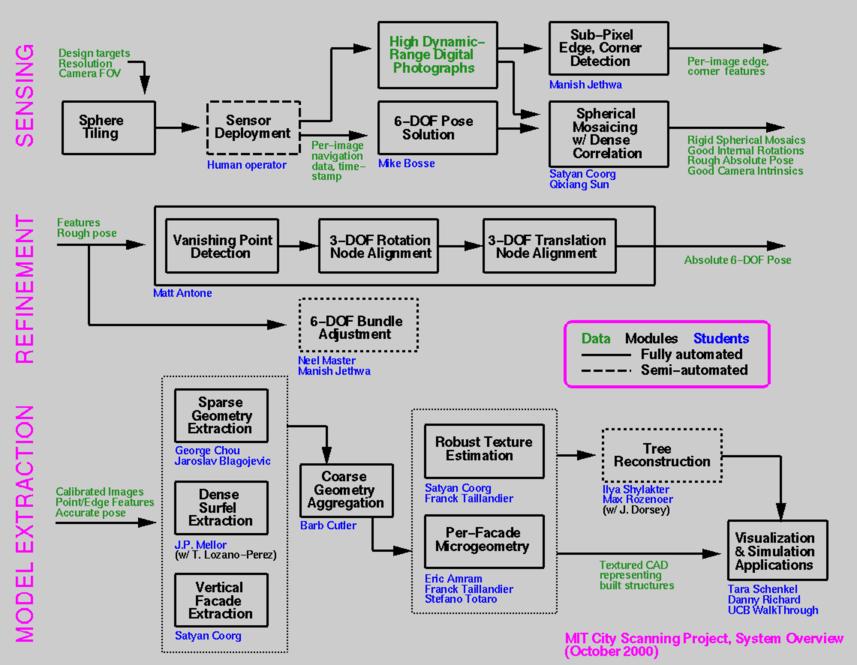
| blockdiagram.jpg | 2000-04-15 16:48 | 159K | ||
| bmg/ | 2005-01-22 16:57 | - | ||
| cambridge3.gif | 1996-11-30 19:07 | 429K | ||
| city.html | 2002-02-02 17:14 | 38K | ||
| city.old | 1997-08-06 16:10 | 3.4K | ||
| code/ | 2002-02-06 15:20 | - | ||
| correlation.jpg | 1999-01-20 19:18 | 129K | ||
| data/ | 2001-10-11 12:48 | - | ||
| datadev/ | 2004-02-09 21:28 | - | ||
| dense3_bw.ps | 1999-07-20 08:59 | 6.0M | ||
| draftPIreport97.ps | 1997-03-11 18:04 | 332K | ||
| eccv2004.old/ | 2004-02-08 09:52 | - | ||
| eccv2004/ | 2004-02-08 11:48 | - | ||
| endtoend.jpg | 2000-10-17 12:12 | 87K | ||
| estimatedtexture.jpg | 1998-06-14 16:05 | 18K | ||
| facade24-align.jpg | 2000-10-17 15:25 | 31K | ||
| facade26-align.jpg | 2000-10-17 15:25 | 30K | ||
| gblocs.txt | 2001-07-19 09:56 | 1.7K | ||
| gpsdata/ | 2001-05-23 19:22 | - | ||
| images/ | 2004-07-28 15:23 | - | ||
| img05_exampleEdges.jpg | 2000-10-20 12:12 | 23K | ||
| img06_spherePoints.jpg | 2000-10-20 12:12 | 21K | ||
| img07_houghTransform.jpg | 2000-10-20 12:12 | 9.3K | ||
| img08_fitPlanes.jpg | 2000-10-20 12:12 | 21K | ||
| img12_vpBeforeAlign.jpg | 2000-10-20 11:58 | 18K | ||
| img13_vpAfterAlign.jpg | 2000-10-20 12:05 | 16K | ||
| index.html.rpmnew | 2003-12-10 05:03 | 2.8K | ||
| interiors/ | 2004-07-28 15:23 | - | ||
| logs/ | 2004-02-09 19:43 | - | ||
| main.mk | 2001-09-24 16:48 | 12K | ||
| main_old.mk | 2001-06-27 15:06 | 7.5K | ||
| manual/ | 2001-11-28 23:08 | - | ||
| model1.gif | 1997-02-26 09:22 | 60K | ||
| model2.gif | 1997-02-26 09:23 | 71K | ||
| models/ | 2002-03-27 08:52 | - | ||
| mosaic.gif | 1997-07-03 17:28 | 123K | ||
| node_warped.gif | 1999-01-26 21:14 | 66K | ||
| node_warped.jpg | 1999-01-26 21:16 | 21K | ||
| nodemap.gif | 1997-07-03 17:42 | 56K | ||
| nttgoal.tif | 1999-12-08 17:26 | 522K | ||
| old_nodelocs.txt | 2001-07-26 17:59 | 30K | ||
| patternmatch.tar.Z | 1999-06-28 08:21 | 4.3M | ||
| quadchart.ps | 1997-07-03 16:56 | 2.7M | ||
| rawtextureobs.jpg | 1998-06-14 16:05 | 19K | ||
| relief-3-notex.jpg | 2000-10-17 15:18 | 69K | ||
| relief-3.jpg | 2000-10-17 15:18 | 80K | ||
| results/ | 2004-07-28 15:23 | - | ||
| robots.txt | 2006-01-26 16:06 | 40 | ||
| rover_1.jpg | 1999-12-08 18:08 | 48K | ||
| servlet/ | 2001-08-01 14:35 | - | ||
| spatialindex.jpg | 1998-06-14 15:20 | 22K | ||
| sphere1.gif | 1997-07-17 10:26 | 104K | ||
| sphere2.gif | 1997-07-17 10:26 | 82K | ||
| sphere3.gif | 1997-07-17 10:26 | 86K | ||
| sphere13.gif | 1997-08-06 16:15 | 87K | ||
| sphere18.gif | 1997-08-06 16:15 | 80K | ||
| sweepplane.jpg | 1999-01-26 21:16 | 55K | ||
| sweepplane_after.jpg | 1999-01-26 21:16 | 54K | ||
| sweepplane_before.jpg | 1999-01-26 21:16 | 55K | ||
| test2.rgb | 2001-06-25 21:55 | 242K | ||
| tiling.gif | 1997-07-03 17:29 | 7.9K | ||
| translation.txt | 2000-10-20 09:58 | 2.6K | ||
| tsq_textured.jpg | 1999-01-26 21:16 | 31K | ||
| tsq_untextured.jpg | 1999-01-26 21:16 | 10K | ||
| video/ | 2004-07-28 15:23 | - | ||
| webapps/ | 2002-01-24 12:42 | - | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}