MIT City Scanning
Project: Fully
Automated Model
Acquisition in Urban Areas
Introduction The "computer vision" or "machine vision" problem is a long-standing, difficult problem. Fundamentally, it is: how can a computer algorithm, alone or in concert with a human, produce a useful computational representation of a scene, given one or more images of that scene? Fully hundreds of researchers have developed machine vision algorithms over several decades. However, they have employed widely different definitions of the problem, leading to an enormous variety of problem statements and proposed solutions, and even degrees of automation of proposed solutions. Researchers have developed algorithms to recognize common patterns (e.g., road networks) or objects (e.g., vehicles) in images, or identify spatial or other relationships among such entities. Others have sought to deduce physical structure from images; for example, the topography of some imaged land area. Still others have used machine vision techniques to monitor automated processes (e.g., robotic manufacturing systems, assembly lines) and human activities (e.g., immigration areas, mall parking lots). Machine vision systems have been incorporated into autonomous and semi-autonomous vehicles, such as cars and helicopters. In all of these contexts, the machine vision problem has proved difficult from both theoretical and practical standpoints. Images are fundamentally ambiguous; they flatten into two dimensions, freeze in time, then clip to fit into a frame, a fully 3D, frameless, temporally continuous world. Cameras, whether film or digital, have low resolution, a small field of view, and limited dynamic range and lightness and color discrimination, compared to the complexity of surface detail, lighting variation, and dynamic range of reflected illumination found in the physical world. Lighting conditions in the real world are enormously complex, as are the surface appearances of even common objects. The usual difficulties of implementing robust numerical and geometric algorithms (ill-conditioned and/or degenerate data) only compound the hardness of realizing working machine vision algorithms. To combat noise and overcome ambiguities in the input, machine vision systems often include humans in the loop, to provide initialization to optimization routines, or crucial identification of or matches between features in images, for example. This inclusion of human capabilities can produce visually impressive geometric models. However, these models are only useful from a restricted set of viewpoints! The most obvious example of this is viewing distance: one can't synthesize a (faithful) close-up view of an object unless one has observed it at close range. Supporting an unbiased viewpoint therefore requires viewing every scene surface at close range. Similar arguments can be made for view direction (to capture non-diffuse reflectance) and occlusion (to capture occluded portions of the surface). We seek to produce view-independent models, and so must acquire many thousands of images; this is too many for a human operator to manipulate. Another consequence of incorporating a human in the loop is that it becomes harder to draw conclusions about what the algorithmic components of the system are capable of, in contrast to the system considered as a whole. Thus there is difficulty inherent not only in defining the problem, but solving it, and evaluating the proposed solution! The state of the art is this. Automated 3D reconstruction systems have been demonstrated at small (sub-meter) scales, under controlled lighting conditions (e.g., indoors on a lab bench), for two or more images and one or a small number of objects. Until now, for example, no researcher has demonstrated an algorithm to register, by tracking or any other means, images acquired from positions extending completely around one or more buildings. When studied closely, algorithmic systems exhibit undesirable asymptotic behavior; for example, many proposed algorithms check all pairs of images for correlation, expending O(n^2) computation time in the size of the input. This imposes a strict scaling limit on the data complexity of the inputs that can be processed. Human-assisted reconstruction systems have been used to recover one or a few buildings (or portions of buildings), but the human is called upon for significant manual intervention, including initializing camera positions and block models of the scene, supplying low-level feature or block correspondences, indicating figure and ground (occlusion and subject). Because a human operator's capacity for work is limited, this too imposes a strict scaling limit on the complexity of the inputs (and outputs) that a human-assisted system can handle. Until now, whether automated or human-assisted, no acquisition system has been demonstrated to scale to spatially extended, complex environments, under uncontrolled lighting conditions (i.e., outdoors) and in the presence of severe clutter and occlusion. The goal of our research and engineering efforts has been to design and demonstrate such a system by combining theoretical advances (new insights and techniques) with solid systems engineering (new sensors and plenty of visualization and validation) and assumptions about the environment (in our case, that urban scenes exhibit some regular geometric structure). We have developed a working, fully-automated prototype system and are now demonstrating it at various scales -- from a few buildings to several hundred, over a square kilometer -- on the MIT campus. We chose to define our problem statement as simply as possible. Given images of an urban environment, we wish to produce a textured geometric CAD model of the structures in that environment. This model should include geometric representations of each structure and structural feature present, and radiometric information about the components of each such entity (e.g., a texture map or bi-directional reflectance distribution function for each surface). One might think of each image as a 2D "observation" of the world; we wish to produce a single, textured 3D CAD model which is consistent with the totality of our observations. Moreover, we wish to achieve a model accurate to a few centimeters, over thousands of square meters of ground area.
The City Scanning Project envisions an end-to-end system to "acquire" such 3D CAD models of existing urban environments. Our principal goal has been to make the system fully automated, so that it scales to handle the acquisition of very complex environments with thousands of structures. Achieving such scaling means mechanizing all aspects of the project. Our first step was the design and construction of a novel device for acquiring navigation-annotated pictures, which we call a "pose-camera" (shown below). [Students: Doug DeCouto and Mike Bosse.] Annotating each image with navigation information (essentially the camera's position and orientation, expressed in Earth coordinates) solves three crucial scaling problems. First, it enables the system to determine, for any spatial region, which cameras were likely to have observed the region -- by virtue of being close by, and pointing in the direction of the region. This eliminates the combinatorial blowup suffered by classical algorithms, which have only the raw images (and no a priori positional information) to work with. Second, the navigation information provides good initialization for the optimization routines that form part of every computer vision system (for example, bundle adjustment for exterior camera control), eliminating the need for human-supplied initialization. Third, since the output model is produced in geodetic coordinates as well, any number of reconstruction systems can operate in parallel to produce results in a single coordinate system.
The pose-camera is a wheelchair-sized mobile platform with a high-resolution color digital camera mounted on a pan-tilt head, which is itself mounted on a vertically telescoping stalk. The platform also includes instrumentation to maintain estimates of global positioning (GPS), heading information (IMU), and dead-reckoning (optical encoders on the wheels), all in absolute coordinates (for example, Earth coordinates). Finally, an on-board power source and PC provide power and control to all of the devices, and disk and tape drives store digital image and pose (position, heading, time) data. We deploy the pose-camera in and around the urban area of interest. The human (student) operator chooses the positions or "nodes" from which images are to be acquired, at a spacing of roughly every 10 meters, maintaining a standoff of 10-15 meters from each building. The pose-camera acquires a spherical mosaic image centered at the node, and annotates it with the on-board instrumentation's estimates of latitude, longitude, and altitude of the camera, heading information, and the date and time, and stores the resulting "pose-image." The pose-camera (which we call "Argus," after the mythical hundred-eyed creature) is nearly complete, and we are field-testing it in and around Tech Square. Here is a recent picture of the Argus, along with Doug DeCouto (whose MEng addresses software control issues for the platform) and Jim Kain of Korbin:

Here is the tiling pattern we use (typically, 47 or 71 images):

Why 47 or 71 images? Around the equator, and at 20 and 40 degrees North, we take twelve images spaced 30 degrees apart. At 60 degrees North, we take nine images (spaced 40 degrees apart); at 80 degrees North, only two images (180 degrees apart). The total is then 12 + 12 + 12 + 9 + 2 = 47 images. Sometimes, nodes are taken from high above ground (e.g., from a nearby building roof, or parking garage top level). These nodes have two extra "rings" of twelve images, at 20 and 40 degrees South, for a total of 47 + 12 + 12 = 71 images. Note that our "tiling" scheme produces overlapping images; this is necessary for the correlation-based alignment stage to produce spherical mosaics (below). Each "tile" of the mosaic is a high-res (1K by 1.5K by 24-bit) digital image:

Here is what the images look like from a fixed optical center as the camera is rotated about it:

Here are the raw images (47 images, 1K x 1.5K x 24 bits each) comprising one node acquired at ground level. Tech Square is visible at left; Draper Labs at right:

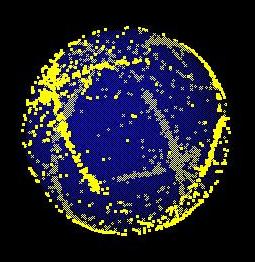
The next step is align each of the images to form a seamless spherical mosaic. We do so by associating a quaternion with each image, then performing numerical optimization to best correlate overlapping regions of neighboring images. Here are several views of one resulting spherical mosaic:



For ease of processing, we use a "spherical coordinate" representation of these mosaics. We coalesce each mosaic into a rectangular pixel array whose horizontal coordinate corresponds to phi (azimuth, from 0 to 360 degrees), and whose vertical coordinate corresponds to theta (altitude, from -90 to +90 degrees). Here is one such "spherical" image, (again) composited from 47 source images:

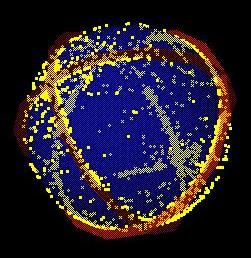
Here is another image, taken at twilight:

What is the "resolution" of these spherical mosaics? Each one represents roughly 1012 x 1524 pixels/image x 47 images, or just under 75 million pixels. Thus, a square texture representing the mosaic would have a resolution of about 8,500 x 8,500 pixels. For technical reasons (basically, so the mosaics can serve well as texture maps inside OpenGL), both their horizontal and vertical dimensions must be powers of two. The closest matching powers of two which produce reasonable aspect ratios (remember, a hemisphere is 360 degrees of azimuth and 90 degrees of altitude) are 8,192 x 4,096 pixels. The mosaics pictured above are decimated; they have a resolution of 512 x 256 pixels, or 1/16th x 1/32nd = 1/512th of the information of the full-scale mosaics! We have also used the Argus and its mosaicing algorithm to acquire some truly high-resolution (say, 8 gigapixel = 128K x 64K) mosaics of interesting interior spaces around MIT, such as Lobby 7. [Students: Mike Bosse, Satyan Coorg, Adam Kropp, Neel Master, Qixiang Sun.]Producing spherical mosaics yields two significant advantages. First, we can treat the mosaics as rigid, "virtual" images with an effective field of view much higher than that of a raw image. In ensuing optimizations, this rigid virtual image can be manipulated as one entity -- reducing, by more than a factor of fifty, the number of free variables to be optimized. Second, the wide effective field of view allows much more robust estimation of vanishing points and translation direction than does a single image. (In typical "frame" images, there is a fundamental ambiguity between small rotations and small translations. This ambiguity does not occur for super-hemispherical images.)
As our Argus prototype became faster and more capacious, we acquired ever-larger datasets in and around MIT. Our most recent dataset includes more than a thousand nodes (and tens of thousands of images) from the main campus. Here is a visualization of an earlier dataset, comprising 81 nodes, registered with a 3D model of Tech Square and a map of MIT:
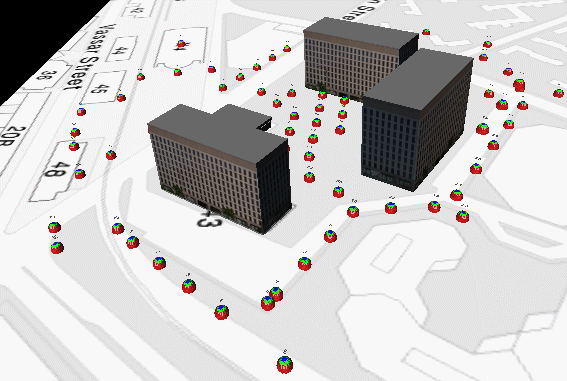
The pose estimates produced by the instrumentation are accurate to 1-2 meters of position and 1-2 degrees of heading. This is good, but not good enough to achieve pixel-perfect registration among images taken from different positions. The next step is to register all images in a common (Earth) coordinate system. (This is called achieving "exterior orientation" by photogrammetrists, even though it requires fixing orientation and position -- six degrees of freedom per image.) Classical registration methods either assume tiny baselines, or use a human operator who manually indicates correspondences among point features in different images. An optimization method known as bundle adjustment then optimizes to find an assignment of camera poses which satisfies the given constraints. Again, small-baseline and human-assisted techniques can work well, but clearly can't scale to large and/or spatially extended datasets.Earlier versions of our system included a human operator to identify correspondences. We have since developed robust, fully automated techniques to register tens of thousands of wide-baseline images acquired under uncontrolled lighting conditions across hundreds of thousands of square meters. Our approach exploits the availability of wide-field-of-view (i.e., super-hemispherical) images, and decouples the classical 6-DOF problem into three smaller sub-problems: a (3-DOF) rotational alignment, a (2-DOF) translational alignment, and a (1-DOF) absolute scale assignment. [Student: Matt Antone.]
Rotational Alignment. The rotational alignment step detects prominent vanishing points (VPs) in the scene. These are points at infinity, representing the direction of sets of parallel lines (edges) in the world, such as rooflines and window edges. Since VPs are at infinity, they are invariant under translation. Moreover, cameras a few meters apart will typically observe the same (or highly overlapping) sets of VPs. We treat the observed VPs as a kind of local coordinate system. By transitivity, if each camera is aligned to this local coordinate system, then the cameras will be aligned with each other. This technique achieves accuracy of about 1 milliradian, or about 1/20th of a degree (this amounts to about 1 pixel in image coordinates). This is twice as accurate as the human-assisted bundle adjustment method described above. The automated system achieves greater accuracy (lower variance) by combining many thousands of noisy but unbiased individual edge observations, whereas the human can manage the processing of at most a few hundred.
Below are some visualizations of the VP detection process.
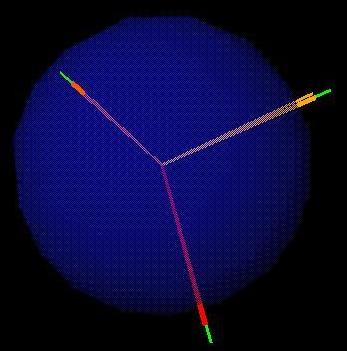
First, at left an example image with three apparent VPs: one horizontal VP from each building, and one vertical VP common to both. To its right is the point cloud on the Gaussian sphere arising from dualizing each edge to the normal of the plane through the edge and the camera's optical center. Note the strong band structure in the point cloud, arising from the superposition of all edges from all images in the subject node. The band structure is much stronger with a wide (super-hemispherical) field of view than it is with a single image. Quantitatively, the VPs can be estimated much more tightly with a wide FOV than with a narrow FOV. To detect the VPs, we must automatically detect and estimate the (visually evident) band structure in the cloud.
......
To do so, we first generate a Hough Transform of the plane normal to each point. For simplicity, we implemented the HT on the surface of a cube of directions, rather than the traditional sphere of directions. Each plane is "scan-converted" to a line-segment (actually a closed curve) on the Gaussian cube. HT buckets in which many segments intersect are evidence of many points lying on the same plane (the normals of those planes are shown in green; these are the detected and initially estimated VPs). We initialize an Expectation Maximization (E-M) algorithm using these peak buckets. The resulting bands are shown in red.
.....
The E-M algorithm then iterates as follows. Each point is weighted by the goodness of its fit to each band (the E-step). Then each band is refit, using the new point weights (the M step). One "outlier" band, with high variance, serves to pick up the points that belong to none of the vanishing points. At convergence (after about five iterations), the E-M algorithm faithfully detects and tightly estimates the band structure evident in the original point cloud.
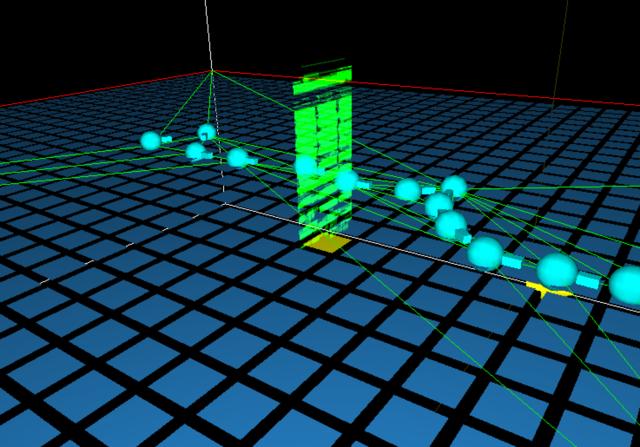
Next, we take the set of VPs separately estimated across each single node, and match VPs across adjacent nodes. This process takes time O(n^4) in the number of VPs in the two nodes, which in practice is less than or equal to five. That is, by matching these "ensemble" or aggregate features, we can avoid having to match thousands of individual edge features. Below at left is the set of VPs arising from one node; at right we show the VPs detected in several nodes, superposed and in the midst of alignment.
....
We use constrained propagation over the entire node adjacency graph to bring all nodes into rotational registration. In practice for nodes acquired with raw estimates good to a couple of degrees, this technique achieves rotational alignment to about a milliradian (a twentieth of a degree), as measured by the variances of the generated VP estimates.
Translational Alignment. Once the cameras have been rotationally registered, we must determine the translational offsets relating the cameras. This problem has only three degrees of freedom, rather than six, because at this stage the cameras are allowed only to translate rigidly, without any rotation. This "decoupling" of the global (6-DOF) registration problem into lower-dimensional subproblems has significant theoretical and practical advantages -- essentially it enables the formulation of a wholly new algorithm which works well in practice for very large, spatially extended image datasets.
Translational registration proceeds in several stages. First, the direction of translation (baseline) between each adjacent pair of cameras is determined. Next, these pair-wise direction estimates are assembled into a global set of constraints to find the relative positions of all cameras. Finally, the relative positions are aligned to absolute (earth-relative) positions by an optimal Euclidean transformation.
The raw navigation estimates supplied by our instrumentation are good to a few meters. Thus, even though we don't know the precise translations relating the images, we do know for each node which nodes were acquired nearby (even across multiple acquisition runs). We compute a Delaunay triangulation of the node positions and call the resulting graph the node "adjacency graph."
Translational alignment first considers each edge of the node adjacency graph, implicating two nodes we'll call node A and node B.
In the first stage, point features are extracted from A and B, and every possible correspondence (match) between points is evaluated. (This takes time proportional to the product of the number of features in the two nodes; however, our feature detector reports only a constant number of features.) Correspondences are ruled out according to hard geometric constraints, such as positive depth and consistency of constituent edge directions. What remains is a small set of putative matches between features (typically numbering between a few hundred and a few thousand), which is then used to refine the initial translation direction obtained from the instrumentation.Since rotations are known at this stage, the epipolar geometry for a given camera pair is simplified considerably. In particular, epipolar lines become arcs of great circles on the sphere, and the epipole, or intersection of all arcs, is the motion direction. This allows us to accumulate intersections between all possible epipolar lines in a modified Hough Transform (HT). The peak, or region of maximum incidence, implicates the likely direction of motion relating nodes A and B.
The HT produces a fairly accurate estimate of the translation direction, good to about a half a degree (we defer the assignment of the magnitude of the translation to a step described below). A subsequent step refines this direction by sampling from the distribution of all possible correspondence sets, thus producing probabilistic correspondence. A Monte Carlo expectation maximization (MCEM) algorithm is utilized which alternates between estimating this correspondence distribution (E step), and finding the direction given the current distribution estimate (M step). This is done by repeatedly generating random perturbations of the probabilistic correspondence matrix, and subjecting the perturbation to a fitness test. Improved guesses are selected, and over several thousand trials the probabilistic correspondence achieved is very good indeed.
This visualization shows the probability matrix evolving for a synthetic dataset. The convergent matrix has correspondences (one's) along the diagonal and discarded matches (zero's) everywhere else.
For a given pair of adjacent cameras, using only features in the images themselves, the translation can be determined only up to scale; that is, we can only find the direction of motion, not its magnitude. Once this direction is found for each camera pair, its (relative) magnitude can be determined by optimizing over a set of linear constraints - namely, the set of all inter-camera motion directions. This is achieved using constrained linear least squares, the result of which is a set of mutually consistent camera positions relative to an arbitrary frame of reference. Thus the algorithm proceeds from local to global registration, first operating on each node adjacency in isolation, then subjecting the entire adjacency graph to optimization.
The final step is to register the resulting camera poses with respect to an earth-relative coordinate frame. The entire set of cameras is
translated, rotated, and scaled according to the global transformation that best aligns the estimated positions with the original (GPS-based) position estimates in Earth coordinates. The final node positions are consistent everywhere to a few centimeters and about one milliradian of heading.The results represent the largest registered terrestrial image datasets in existence, to our knowledge.
Early Datasets
Here is a visualization of 10 of the 81 nodes, co-located in a common coordinate system with the Tech Square CAD model. This is a visualization of 500 images, each 1.5 million pixels -- almost 750 million pixels total! (All 81 nodes together comprise more than 6 billion pixels!)

Here is the full dataset, with texture applied to each spherical node:

Once the spherical mosaicing and absolute pose determination are complete, we have achieved a valuable, and fundamentally novel, collection of data which we call a pose image dataset. Our algorithms treat pose-images (images annotated with 6-DOF information about the position and orientation of the acquiring camera) as first-class data objects, much as earlier algorithms treated raw images. Our goal is to perform reconstruction of urban structures directly from large numbers of pose images. (This is in contrast, for example, to existing algorithms which simultaneously estimate camera pose and 3D structure.)We are developing several algorithms to perform 3D reconstruction. The algorithms have different attributes. Some are sparse, or feature-based; they attempt to infer structure based on proximity of entities like vertices or edges. Others are dense, or region-based; they attempt to infer structure (e.g., building facades) by identifying large numbers of pixels which appear to lie on the same surface. [Students: Jaroslav Blagojevic, George Chou and J.P. Mellor. J.P. Mellor co-advised by Prof. Tomas Lozano-Perez.] A more recent approach, related to the space-carving method of Seitz and Dyer, uses voxels and multi-scale image processing to extract a volumetric representation of the scene. [Student: Manish Jethwa.]
Another reconstruction algorithm uses no feature correspondence. Instead, it uses edge histogramming to identify and localize prominent vertical facades under the assumption that such facades exhibit many horizontal edges. [Student: Satyan Coorg.] First each edge is color-coded by the orientation (in degrees, say from 0 to 360) of its presumed vertical facade:

Under this bucketing scheme, facades reinforce a bucket not only across a single image, but across multiple nearby images (due to the rotational registration.) The histogramming technique produces a peak whenever many edges reinforce a single facade, yielding the orientations of dominant facades in the scene. Finding their positions requires sweeping a plane through the relevant spatial region of the dataset.
This technique yields facade geometry, but not texture (which also goes by the name of reflectance, albedo, or BRDF -- bidirectional reflectance distribution function). Here's the extracted geometry, which is faithful to the buildings in the original scene, but looks rather coarse and unrealistic:

There is an enormous amount of information about the buildings' appearance in the original photographs. Much of it is either corrupted by noise, occluded by modeled structure, or obscured by scene clutter -- people, cars, trees, et cetera. However, the noise, occlusion, and clutter arise incoherently across many images. The building surfaces, on the other hand, arise coherently, in the sense that multiple observations of a given surface reinforce eachother. Thus we are able to combine many different views of a building to produce a single, high-confidence estimate of what the building "really" looks like. In a real sense, the Argus can "see through" trees and other clutter by combining observations in this way! We call this high-confidence estimate the "consensus texture" for the building surface.We estimate a crude diffuse texture using weighted median statistics. Here are some screen shots of the 3D model generated by the algorithm, overlaid on a geo-registered aerial image. You can also view MPEG videos by following the links at the top of this page.

We can extract block models, and map textures onto them. At this stage, the resulting models still have a sort of "painted shoebox" look, since the underlying surfaces are completely flat. Real buildings, even blocky ones, are not completely planar; window moldings, balconies, entrances etc. give rise to depth variations or "relief" on each building surface. Thus the next stage of processing takes the coarse models produced above, and the raw images (with most occlusion and clutter masked away), and produces detailed surface models for each building facade. In contrast to the earlier processing stages, here we assume a great deal about the way windows and window grids occur on buildings. These assumptions are valid for most buildings, but not all. [Students: Xiaoguang (XG) Wang and Franck Taillandier. XG Wang co-advised by Prof. Allen Hanson.]Here's an example consensus texture and the window grid extracted from it:
The window grid is analyzed for periodicity, window width, height, spacing, etc., and then regularized. False negative and false positive windows are largely avoided by appeal to edge observations from the original images. [Student: Franck Taillandier.] We then constrain an algorithm originally developed for terrain estimation (due to Fua and LeClerc) to respect the presumed window boundaries on each each facade. One resulting facade is shown here without texture:
The same structure is shown with texture below. The procedurally-generated roof and ground polygons and texture have been suppressed in order to show precisely what the automated relief algorithm generates.
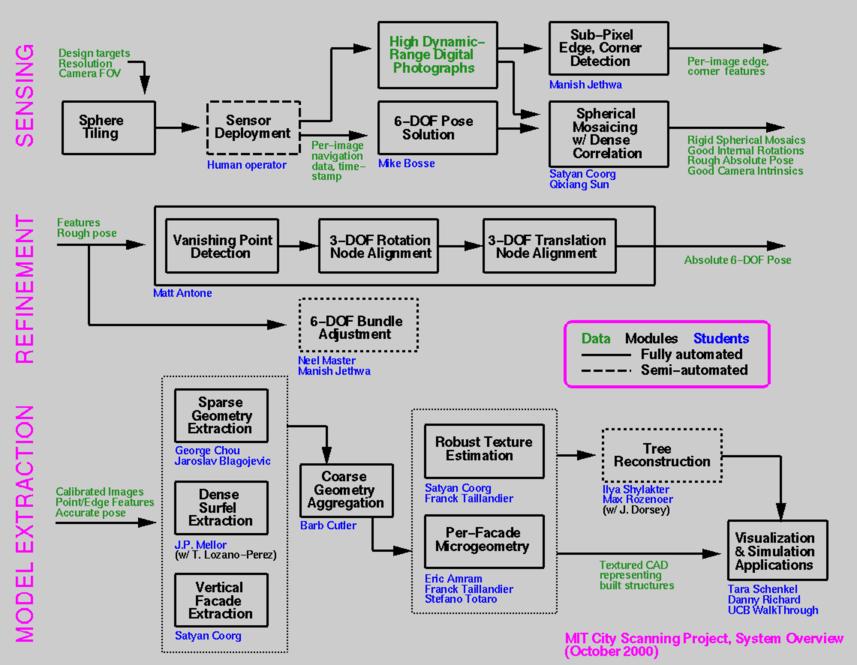
Here is a block diagram of the system. It is organized into three major stages (shown as rows, and labeled at left): Sensing, Refinement, and Model Extraction.
All of our algorithms employ sophisticated spatial data structures to represent 3D space, and sometimes space of lower or higher dimensionality. For example, we use octrees to perform "incidence counting" of point features in 3D, and line features in 4D. We use sweep-plane algorithms to identify prominent vertical facades. And we use spatial indexing of pose-images to identify "relevant" pose-image subsets, given some region of 3D space on which we wish to focus.
What's next?
There are dozens of interesting directions in which to take the system, but because we don't have infinite resources we are pursuing just a few.First, we are continuing our validation efforts by hiring an independent surveying firm to establish "ground control" at a number of points on campus, and characterizing our navigation sensor with respect to it.
Second, we are investigating whether a low-resolution (omnidirectional video-based) version of the sensor can be made to work in real-time, or near-real-time. Some environmental features may be harder to detect robustly at video resolution.
Third, we are extending our data collection and algorithms to multi-floor, indoor architectural scenes. This brings up a host of research issues, for example getting along without GPS; assuming less about visible architectural features; handling more complex geometry and clutter; handling multi-floor geometry.